The Human Mortality Database: This database includes detailed population and mortality data for 41 countries. In response to the COVID-19 pandemic, the team behind the database has started compiling weekly death counts, which can be used for excess death calculations; they have compiled counts for 34 countries so far.
SARS-CoV-2 Superspreading Events: Superspreading events, or instances in which many people are infected with the novel coronavirus at once, have been identified as a major force behind the spread of COVID-19. This database includes over 1,400 superspreading events from around the world, with information on each event’s timing, location, inside/outside setting, and more.
COVID-19 Risk Levels Dashboard: A new map from the Harvard Global Health Institute and other public health institutions allows users to see the COVID-19 risk for every U.S. county. These risk levels are calculated based on daily cases per 100,000 population (7-day rolling average).
This newsletter is about to step up its game in a big way. I am absolutely honored and thrilled to announce that I’ve been selected for the inaugural cohort of the Entrepreneurial Journalism Creators Program.
This program is a new 100-day course from the Craig Newmark Graduate School of Journalism at the City University of New York. Starting this coming week, I will learn how to better understand the needs of my audience (that’s you!) and develop a sustainable journalism project. The other 19 students in my cohort include journalists from around the world, working on projects ranging from local news to global health reporting. You can read more about the program and its participants here.
I’m incredibly grateful to all of the readers who have supported this project so far, whether you subscribed to my first issue or just found this newsletter last week. Thank you for your support and feedback on how I can best make COVID-19 data accessible. I’m excited to share what I learn in my course with you, and to grow the scope and resources offered by this project.
The county-level testing dataset published by CMS has become a regular topic for this newsletter since it was released in early September. As a refresher for newer readers: CMS publishes both total PCR tests and test positivity rates for every county in the country; the dataset is intended as a resource for nursing home administrators, who are required to test their residents and staff at regular intervals based on the status of their county.
This past Monday, October 5, I was pleasantly surprised to find a new update posted on CMS’ COVID-19 data page. I say “surprised” because I had been led to believe, both by past dataset updates and by reporting when the dataset was first published, that this source would be updated once every two weeks. And yet, here was a new update, with only one week’s delay (the last update before this was on Monday, September 28). CMS is also now posting weekly updates on an Archive page which goes back to August 19; some of these updates are older, while others were posted or edited in the past week.
I always appreciate more frequent data, even when the data provider in question is not particularly transparent about their update strategy. Frequent updates are particularly useful for testing data; the nursing home administrators monitoring testing in their counties will be able to see information that better reflects the level of COVID-19 risk around them.
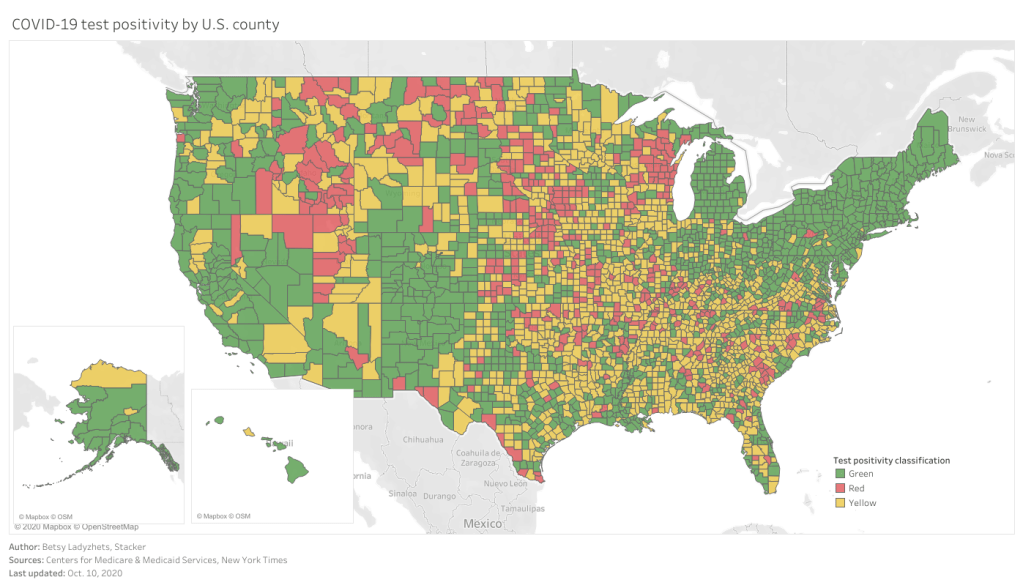
As you can see, the majority of the Northeast and much of the West Coast continues to be in the green (positivity rates under 5%), while areas in the South and Midwest are not faring so well. Twelve counties have extremely high positivity rates (over 30%), eleven of which are in Midwestern states. This table allows you to rank and sort the test positivity rates by state.
Also, a note on my methodology for this dashboard: in earlier iterations, I used state-level data from the COVID Tracking Project to calculate state test positivity rates for the same time period as the CMS has provided county-level rates. I then compared the county-level rates against state-level rates; this was the source of the “[x]% above state positivity rate” tooltips on the dashboard. After reading a new COVID Tracking Project blog post about the challenges of calculating and standardizing positivity rates, however, I realized that combining positivity rates from two different sources might misrepresent the COVID-19 status in those counties. So, I switched my method: the county-to-state comparisons are now based on averages of all the CMS-reported county-level positivity rates in each state.
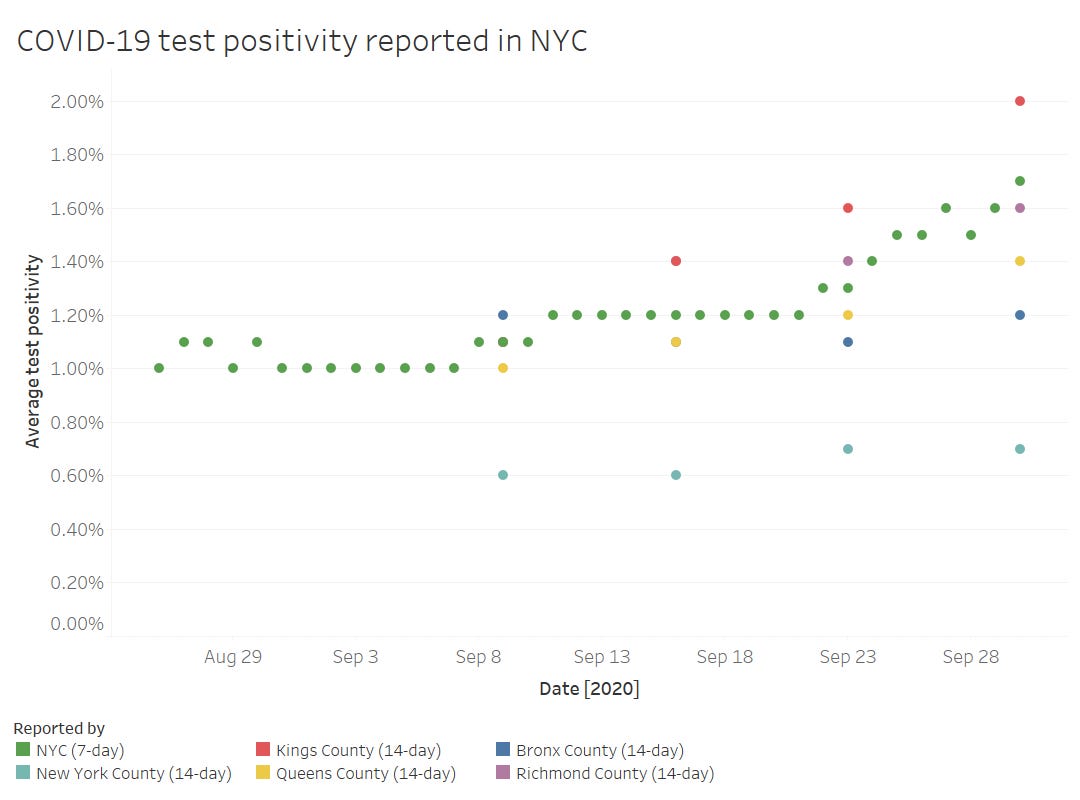
Finally, out of curiosity (and to practice my Tableau skills), I compared the CMS-reported test positivity rates for the five counties of New York City to the city-level rate reported by the NYC Department of Health.
The positivity rates reported by the two sources follow the same general direction, but it’s interesting to see how the rates diverge when the five counties split up. Manhattan remaining far below 1% while Brooklyn surges up to 2%? Not surprising.
Meanwhile, CMS is cracking down on COVID-19 reporting from hospitals: NPR reported this week that hospitals which fail to report complete, daily data to HHS can lose money from Medicare and Medicaid, starting this coming January.
Abbott ID NOW tests, pictured at a health clinic in Williamsburg (my photo).
Two weeks ago, I went to my COVID-19 testing site of choice for a post-Maine trip screening. I walked the now-familiar ten blocks to the site, a private clinic in Williamsburg, and waited at the now-familiar counter for one of the receptionists to be available to check me in.
“Do you want a rapid test?” the receptionist asked.
“No, PCR, please,” I replied.
I had assumed that the “rapid test” she offered was an antigen test. Antigen tests, as I’ve described in this newsletter before, have a low sensitivity, meaning that they may miss identifying people who are actually infected with the novel coronavirus. (These missed cases are called false negatives.) Evidence also suggests that antigen tests will return more false negatives for patients who are asymptomatic. As I was not exhibiting COVID-19 symptoms, and rather wanted to get tested because I had recently traveled out of the state, I was interested in receiving a more accurate test.
But confusion quickly ensued: the rapid test that my clinic offered, as it turned out, was not an antigen test. It was a nucleic acid amplification test—a model manufactured by Abbott called the ID NOW. Like PCR (polymerase chain reaction) tests, this test uses gene amplification to identify genetic material associated with the novel coronavirus in a patient’s mucus sample. But unlike PCR tests, the ID NOW test does not require clinics to send samples out to faraway labs for processing. This test is distributed with small, in-house DNA amplification machines that can provide patients with their results in 15 minutes. I got the result of my ID NOW test later that same afternoon. (And then I got the results of a second test, this one a PCR test which I had asked the clinic to request at a lab, several days later. Both tests were negative.)
I hadn’t heard of Abbott ID NOW tests before last week. But they’re in the news now, connected to what has become America’s most infamous COVID-19 outbreak: President Trump’s White House relied on Abbott ID NOW tests. And they used these tests incorrectly.
No test type specification in molecular testing data
Rapid testing has been the White House’s defense against critiques of COVID-19 carelessness, explains Slate reporter Daniel Politi. Each day, staffers would get tested with Abbott ID NOW tests. Upon receiving negative results, staffers would be cleared to take off their mask and act without consideration for social distancing. Boxes of the ID NOW tests used for this screening have been pictured at the White House since March.
But how accurate are those negative results? If you’re asymptomatic: not very. The ID NOW test is only authorized for use in people with symptoms. A guidance from the Food and Drug Administration (FDA), updated on September 17, specifies:
The ID NOW COVID-19 is authorized for use with respiratory specimens collected from individuals who are suspected of COVID-19 by their healthcare provider within the first seven days of the onset of symptoms.
The majority of White House staffers who were tested with these tests had not been coughing and wheezing, nor had they been suspected of COVID-19 by a healthcare provider. In asymptomatic patients like these, as many as one-third of negatives returned by the ID NOW test may be false negatives. It’s no surprise, then, that the virus spread quickly through an indoor environment where staffers were using rapid tests—but doing little else.
White House staff are not the only people who used the wrong type of test to check their COVID-19 status. I shouldn’t have gotten an Abbott ID NOW test either. But when a nurse at my local clinic, which I saw as a site of trusted health expertise, offered one to me, I didn’t ask too many questions. It’s PCR, I thought. It’ll be accurate.
But first of all: the Abbott ID NOW test is not a PCR test. It’s in the same family as PCR tests (molecular-based, DNA amplification), but it operates on a different paradigm. And second of all, the health care workers at my clinic gave me no indication of how accurate this rapid test was, especially for my asymptomatic self. (Note: I have no hard feelings toward this clinic or any of the workers there. I’m simply using my own experience as an example of how poorly information about test types is conveyed to the public in general.)
What if my PCR test, sent out to a lab, had returned a positive result? I would have traversed Brooklyn, gotten groceries, grabbed coffee at a neighborhood cafe, and attended a protest in Queens that weekend, buoyed by a negative result yet unknowingly spreading the coronavirus to my fellow New Yorkers. And both of my tests would have been accounted for on New York’s testing dashboard in one single tick mark. New York reports tests in encounters, so my two specimens would have been deduplicated as simply “one person tested on September 30.”
I say “would have been” because I am not, in fact, sure that my Abbott ID NOW test made it into the New York Public Health Department’s database at all.
Here’s a line from the press release that Abbott put out on October 2, the day that Trump tested positive:
While we don’t know the details on who was tested and on which devices, we know that more than 11 million Americans have taken the ID NOW test, helping to stop the spread of the virus.
11 million is a pretty big number: if these tests were all included in the national count reported by the COVID Tracking Project, they would make up about 10% of the total. But are the ID NOW tests included in the COVID Tracking Project’s count? It is difficult to say. The majority of state public health departments, the sources for the COVID Tracking Project’s data, simply report total counts of nucleic acid-based tests, if they specify their test type at all.
State COVID-19 dashboards fail to separate out test counts by method or manufacturer. Some states, such as Maine and Illinois, acknowledge that their test counts include all “nucleic acid-based tests,” not only the PCR tests which fall into this category. Other states, such as Oklahoma and Florida, report detailed data about the testing capacity of individual labs and point-of-care facilities, but fail to supply the testing models used at each location. South Carolina acknowledges a small number of “unknown” tests, for which the public health department is investigating possible categorizations. The Department of Health and Human Services, meanwhile, only reports PCR tests, absent counts of any other molecular test type.
And, returning to Abbott’s press release: the manufacturer admits that they “don’t know the details on who was tested and on which devices.” This leaves a lot of open questions about how rapid testing data are being collected; Abbott seems to imply that even the manufacturer itself does not have access to specific information about where and how their tests are in use. If I had to guess, I’d say that 11 million figure comes from bulk test orders sent out by facilities like my local clinic.
It’s great for healthcare responses that Abbott tests can be processed quickly on-site, in facilities like a healthcare clinic or a major political site. But public health departments don’t have relationships with clinics—they have relationships with testing laboratories. When tests aren’t sent out to a lab, it’s easy for them to fall through gaps in a data pipeline which relies on complex electronic reporting systems. (This is also a problem for antigen tests.)
So, the problem stands: Abbott ID NOW tests are in use across the country. 11 million of them have been distributed since March. But where are the tests being used, how many of them have returned positive results, and are they being used correctly—to quickly diagnose patients with COVID-19 symptoms? Without these data, it is difficult to determine whether Abbott’s test should be part of America’s testing strategy going forward.
Conflating antigen and PCR tests
I can’t discuss the data pitfalls of rapid COVID-19 testing without devoting a few paragraphs to antigen tests.
Five days before his positive COVID-19 test was made public, President Trump announced a plan to deploy 150 million antigen tests across the country. 100 million tests will go to state and territory public health departments, while the remaining 50 million will go to facilities supporting vulnerable populations such as nursing homes, hospice care facilities, and historically Black colleges. Trump discussed how useful antigen tests could be for screening, suggesting that teachers could be tested regularly.
The tests Trump praised are rapid antigen tests manufactured by Abbott, which received FDA Emergency Use Authorization at the end of August. Abbott’s antigen tests are cheap—each one costs $5. And, like the ID NOW tests, they’re fast—patients receive results in 15 minutes. But, also like the ID NOW tests, antigen tests are more effective for symptomatic people.
Here is how Alexis Madrigal and Rob Meyer explain it, in an article for The Atlantic published this past week:
If distributed en masse and used to screen asymptomatic people, these antigen tests will deliver hundreds of thousands—if not millions—of false results, they say. False negatives could lead to reckless behavior by people who don’t know they’re sick. False positives can also put people at risk: If a virus-free nursing-home resident with a false positive is placed in a COVID-19 ward, that person could become infected.
This is not to say that antigen tests are useless; their utility is still being debated in epidemiological and public health circles. The advantages of these cheap, fast tests may outweigh the dangers of their low sensitivity. But to truly understand this problem, we need access to better antigen test data—not just 60 tests from Nevada nursing homes (the sample size upon which that state’s decision was made).
If 11 million Abbott ID NOW tests are a data concern, 150 million Abbott antigen tests are a data minefield. For the past month, I’ve been working on an analysis for the COVID Tracking Project which covers how states are reporting—and failing to report—antigen test results. This analysis is set to be released in the next week, in all its detailed glory. But I can tell you now that the majority of states are not reporting antigen tests in separate counts from DNA-based tests, just as the majority of states are not reporting other types of DNA-based tests as separate from PCR tests. In fact, several states now specifically report that their testing counts combine PCR and antigen tests in one figure.
When two different test types are conflated in a single total figure, it is difficult to analyze the progression of how either test is being used. I can’t tell you how many antigen tests are being put to use across the country, or how effective they are at containing COVID-19 in a given community, if these test numbers are lumped in with another test type. Test lumping also presents a(nother) challenge for test positivity calculations, as antigen and PCR tests have very different sensitivity levels.
And even the few separate antigen test counts that states do report are likely significant undercounts of the actual scale of antigen testing going on in the U.S. As I mentioned earlier, no data reporting pipelines are set up for tests that occur rapidly in point-of-care settings. The Center for Medicare & Medicaid Services (CMS) does not report the number of antigen tests that have occurred in nursing homes, for example.
So far, it appears that state and federal public health agencies alike are unprepared to report the results of antigen tests. Before the White House deploys its 150 million Abbott antigen tests, I hope to see that change.
Search trends on COVID-19 symptoms: Researchers can now access a Google Search dataset of search trends related to over 400 COVID-19 symptoms and related health conditions, such as fever, cough, and difficulty breathing.
FAQs on Protecting Yourself from COVID-19 Aerosol Transmission: This pubic document was compiled by a group of scientists and engineers who study aerosol transmission. Answered questions range from “How long can the virus stay in the air indoors?” to “What is the best type of mask?”
MIT COVID-19 Indoor Safety Guideline: Another air transmission resource allows users to calculate the risk levels for different indoor spaces, based on a model by MIT researchers Martin Bazant and John Bush.
Open States COVID-19 Legislation: Open States, a public civic engagement project, is compiling a list of legislation related to the COVID-19 pandemic in the U.S. The database currently tracks over 3,000 bills in 46 states.
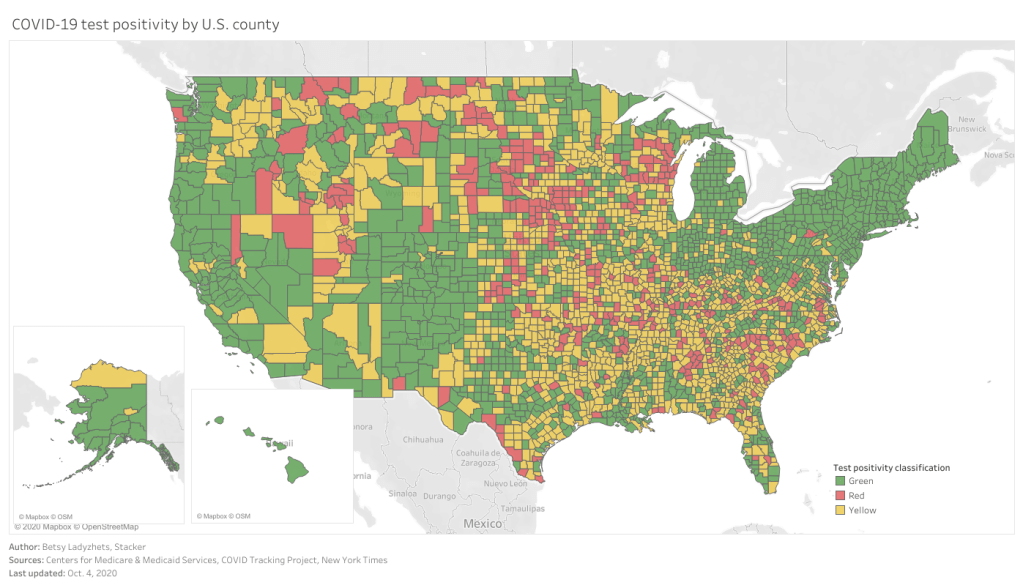
This past Monday, September 28, the Centers for Medicare & Medicaid Services (CMS) updated the county-level testing dataset which the agency is publishing as a resource for nursing home administrators.
I’ve discussed this dataset in detail in two past issues: after it was published in early September, and when it was first updated two weeks ago. The most recent update includes data from September 10 to September 23; CMS is continuing to analyze two weeks’ worth of testing data at a time, in order to improve the stability of these values. And this update came on a Monday, rather than a Thursday, decreasing the data lag from one week to five days.
A CMS press release from this past Tuesday describes one update to how CMS assigns test positivity categories, which nursing home administrators look at to determine how often they are required to test their patients and staff:
Counties with 20 or fewer tests over 14 days will now move to “green” in the color-coded system of assessing COVID-19 community prevalence. Counties with both fewer than 500 tests and fewer than 2,000 tests per 100,000 residents, and greater than 10 percent positivity over 14 days – which would have been “red” under the previous methodology – will move to “yellow.”
This change intends to address the concerns of rural states which are not doing much testing due to their small populations.
I’ve updated my Tableau visualization with the most recent county data. The majority of the Northeast continues to be in the green, while areas in the South and Midwest pose higher concerns.
President Trump and the First Lady tested positive for COVID-19 in the early morning on Friday, October 2. As I draft this newsletter on Sunday morning, at least 15 other people connected to the President have tested positive, ranging from Bill Stepien, Trump’s campaign manager, to New York Times Washington correspondent Michael Shear.
You might expect me to source this number and these names from a federal public health agency, which is conducting all of these tests and making their results public. Not in this pandemic! My source is, of course, a dashboard compiled by volunteer journalists and science communicators.
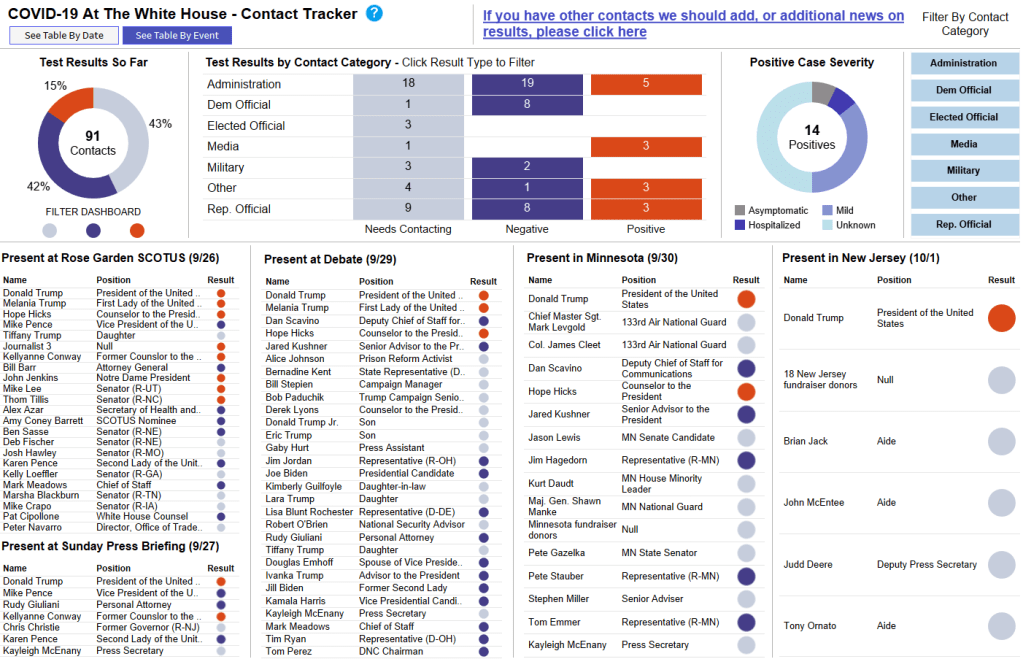
This dashboard, called the COVID-19 At The White House Contact Tracker, is attempting to trace over 200 contacts in connection with the President and his staff. The team behind it includes Benjy Renton, independent reporter on COVID-19 in higher education, Peter Walker, data visualization lead at the COVID Tracking Project, and Jesse O’Shea, MD, infectious disease expert at Emory University.
The Contact Tracker is an incredible public service. In its current form, the dashboard lists 235 White House contacts who should get tested for COVID-19, along with their positions, test results (if known), symptoms (if they test positive), and the date of their most recent test. You can also view the data as a timeline, based on each person’s last contact with the President, and as a map based on the Rose Garden ceremony, the debate, and two other potential spreading events.
It is not surprising, after months of poor data reporting from the federal government that, instead of the CDC or the HHS, the best source of data on this high-profile outbreak is—as Dr. O’Shea puts it— “three awesome dudes [contact tracing] from our homes.” But it is worth emphasizing.
we are seeing a super spreader event of high-profile politicians driven by a supreme court ceremony, & the best source of data on the outbreak is a tableau dashboard thrown together by a couple of independent journalists!!! not surprising at this point but it has to be said!!!!
What are federal public health agencies prioritizing right now, you might ask? The HHS is planning a $300 million-plus ad campaign with the goal of “defeating despair” about the coronavirus. And this money came out of the CDC’s budget. I was planning to devote a bigger section to this campaign before COVID-19 hit the White House, but instead, I will direct you to an excellent (and terrifying) POLITICO feature on the subject. Dan Diamond also discusses his investigation of the campaign on his podcast, POLITICO’s Pulse Check.
The COVID-19 School Response Dashboard has surveyed nearly 1,000 individual schools and districts on their enrollments, case counts, and COVID-19 mitigation strategies. Screenshot retrieved on October 3.
The data sources on COVID-19 in U.S. K-12 schools vary widely, but most of them have one thing in common: they only report case counts.
Texas rescinded school data this past week due to errors. Florida recently began publishing school reports—which list out cases by individual school while failing to provide cumulative totals. But a larger problem for these states and others is that, when case numbers are reported in isolation, there is no way to compare outbreaks at different locations.
Imagine, for example, that you only knew that Wisconsin had seen 18,000 cases in the past week, while Texas had seen 28,000. You would assume that Texas is currently in more dire straights, with more people infected. But adjust for population—divide those case numbers by the populations of both states—and you find that Texas has an infection rate of about 95 people per 100,000 Texans, while Wisconsin has a rate of about 303 people per 100,000, over three times higher. Texas is slowly recovering from its summer outbreak, while Wisconsin is an outbreak site of major national concern.
In the case of school data, enrollment numbers are the key to these comparisons. Knowing how many students are infected in your district may be useful, but unless you know how many students are actually going into school buildings on a regular basis, it is difficult to translate the case numbers into actionable conclusions. The majority of states which report school COVID-19 data do not report such numbers, and even those that do may have incomplete data. New York’s dashboard, for example, currently reports 0 staff members in the New York City school district, which opened for in-person instruction last week.
Volunteer datasets similarly focus on case numbers. The National Education Association School and Campus COVID-19 Reporting Site, built from the crowdsourced spreadsheet of Kansas high school teacher Alisha Morris, compiles case counts from news outlets and volunteer reports. The COVID Monitor, a school dashboard produced by Rebekah Jones’ Florida COVID Action project, combines news and volunteer reporting with state-reported numbers. Both of these efforts are incredibly comprehensive in documenting where COVID-19 is impacting students and teachers, but without enrollment numbers for the schools, it is difficult to use the data for meaningful comparison.
Even the New York Times focuses on case counts. The Times’ review of school COVID-19 cases found extremely scattered public reporting, but the paper failed to include any denominators—not even the county case counts which this paper has been tracking since early in the pandemic. Alexander Russo, columnist at education journal Phi Delta Kappan and friend of this newsletter, recently commented on how such cases-only reporting may paint a misleading picture of the pandemic’s impact.
Clearly, we need denominators for our case counts. And a new dataset is out to provide this crucial metric. Emily Oster, Professor of Economics and Public Policy at Brown University, collaborated with software company Qualtrics and several national education associations to build a COVID-19 school dashboard which focuses on case rates, not counts.
This project sources data by directly surveying schools every two weeks, rather than relying on sporadic news and volunteer reports. And it includes information about school reopening plans and mitigation strategies, such as whether masks, increased ventilation, and symptom screenings are in use. As of the dataset’s most recent update (for the two-week period of September 14 to 27), 962 schools in 47 states are included. These schools report an average student infection rate (confirmed and suspected cases) of 0.62% and an average staff infection rate of 0.72%; both rates are up from 0.51% and 0.5%, respectively, in the previous two weeks. For more initial findings, see this NPR feature on the dashboard, published on September 23.
I spoke to Oster this past Tuesday, only four days after the dashboard’s public release. She explained more detail about the project’s methodology and her future plans for tracking COVID-19 in schools. (This interview has been lightly edited and condensed for clarity.)
Interview
Betsy Ladyzhets: What is your background in data and education reporting? What have you been working on during the COVID-19 pandemic that led you to this dashboard?
Emily Oster: I am, by training, an economist, so I have a lot of background in data analysis and some in data collection. But most of my work, virtually all of my work has been on health, not on education. I have written a couple of books on pregnancy and parenting, so I have this audience of parents. And during the pandemic, I was writing a lot about kids and COVID. And then that led me to be interested in issues around schools, and putting together this team to do the data collection for the dashboard.
BL: Who else is on the team?
EO: The partnership—the primary people who are doing the work and analysis—is Qualtrics, which is a tech company. And then, there are a number of educational association groups. The School Superintendents Association, the National Association of Elementary School Principals, the National Association of Secondary School Principals, that was the initial core team. Then, we’ve got a lot of distribution help from the charter school alliance, from a bunch of the independent schools associations. A lot of different educational groups have done distribution work.
BL: How did you develop partnerships with these different education groups?
EO: I had expressed in some public forum that I thought there should be more of this data collection, and someone from Qualtrics reached out and said, “We think there should be more of this, too. Maybe we can help.” And around this time, I was connected with a woman at the school superintendents association, who also said, “I think we should do this, maybe we can help.” Those were the two key pieces, and it came together from there.
BL: Yeah, it’s good to have—it seems like a very useful partnership, that you have the tech expertise but also the people who are actually interacting with teachers and students.
EO: Yeah. I think our biggest get for the dashboard, and what is potentially useful about it, is that we start at the school level. We know what the schools are doing. We’re in direct contact with them.
BL: I know from poking around the dashboard and reading the NPR article that the way you’re gathering data is with that direct interface, surveying schools. Why did you choose this method as opposed to looking at news articles or compiling data from public sources?
EO: It was really important for us to understand the context around school reopening before we asked about the COVID cases. We really wanted to know: how many kids do you have in school, are they actually in school or are they virtual, what kind of enrollment do you have? And also, what are you doing as mitigation? To come, ultimately, to understand what’s happening with cases, we really need to start by understanding, like, are you wearing masks? Are you distancing? Are you doing all of these things? So then, if we do see cases, we can go back and look and say okay, can we make any conclusions about which of these precautions are helping.
In particular, these enrollment numbers give us the ability to say something about not just cases, but rates. To be able to say, this is the share of people that are infected. Which I think is a very important number, and arguably more important for decision-making, than counts.
BL: Yeah, I was going to ask about that. Your dashboard, unlike a couple of other school COVID data projects, actually has denominators, so that you can compare case rates.
EO: That’s our thing. That’s our whole pitch. We have denominators.
BL: Why is it so important to have denominators?
EO: I think the importance of denominators is, it tells you something about the actual risk of encountering someone with COVID… If you’re going to send your kid off to school, and if you’re going to send your kid to a school of 1,200 people, I think it is useful to understand—are there likely to be 100 kids in the building with COVID? Is there likely to be one kid in the building with COVID?
And similarly, thinking about the risk to your kid, if your kid is going to be in the building for two weeks, what’s the average experience? Is there a ten percent chance they’re going to get the coronavirus over these two weeks? Is there a one percent chance? I think that that is the thing we should be making decisions on. We really need those denominators to get the rate.
BL: Absolutely. Could you tell me more about how the surveys work? What questions you’re asking, and how often you’re collecting data?
EO: There’s two different avenues for data collection… First, if you’re an individual school, then the way we’re collecting the data is that you enroll in a baseline survey on Qualtrics. We ask you about your enrollment, your opening model, what share of your kids are in person, how many staff you have, are they in person. And then, if you have in-person instruction, we ask you about masking and distancing, what you’re doing on those conventions. And then we ask maybe one or two demographic questions, like are you doing free or reduced-price lunch, or financial aid if it’s a private school.
That [initial survey] is followed up every other week with a survey that is very short. It’s basically, how many confirmed and suspected cases do you have in students and staff, and then [we ask schools to] confirm their in-person enrollment, just to see if there have been large changes in the opening model.
And then, on the district side, we’re asking all the same questions, but—in the case of the districts, there are a number where [superintendents] have said, “We’d like to enroll our entire school district in your thing, and we’re going to give you all of our data.” When we do that, we’re actually collecting the data internally in Excel. We send them an Excel sheet with their schools, they fill out that same information [as in the school survey], and then we come back again biweekly and ask them those same questions. It’s the same information, it’s just that rather than making them go through 25 versions of the same Qualtrics survey, we have it all in one.
BL: What mechanisms do you have in place for flagging errors? I know that’s a concern with this kind of manual back and forth.
EO: On the district side, there’s a cleaning procedure. When the surveys in, obviously we don’t change them, but we look them over. If there’s something that’s wrong, like the number of COVID cases is greater than the number of people, or they’ve reported three billion students enrolled, we go back to the district and ask, “Can you look at this?”
Then, on the individual school side, there’s a bunch of validation built into the Qualtrics survey operation. And we have some procedures which we’re working on ramping up which are going to do a little bit of hand lookup, just to make sure that we’re getting valid data.
BL: What is your sample of schools like so far? Is there a particular area, like any states or types of schools that you have more complete data so far, or any areas where you’re prioritizing in trying to get them to take the surveys?
EO: We’re an equal opportunity prioritizer. We’ll take anybody. There are a few states where we have better representation of private schools, because [private school associations are involved in roll-out]. We have more schools in Washington than elsewhere.
Particularly on the public school side, we’re very concerned about enrolling entire districts. That’s the easiest thing for us, it’s the most robust. It is also—we think it provides the most service to the district. And so we are spending a lot of time doing outreach to states and to districts, trying to get people to encourage their districts to enroll.
BL: Another thing I’m curious about is testing. Just yesterday, the Trump administration announced that they’re going to deploy 150 million rapid antigen tests around the country, once they’re made by Abbott, and they’re going to focus on getting those tests to students and teachers. Is testing something that you’re thinking about tracking?
EO: Yeah. We ask [the schools], are you doing any routine testing of anybody, and most them say they’re not. But I think it would be very interesting to incorporate. Part of my hope for this project is that, over time, as we get more people enrolled and we get more of a rhythm of reaching people routinely, that there will be questions we can add. We’ll potentially get to a place where we’ll say, “Okay, now, a bunch of districts are doing testing, let’s put that in.” And we’ll try to figure out, how common is that, and who’s doing it.
BL: There are also states that are reporting COVID data in schools. I know New York has a dashboard, that’s pretty extensive, while other states report numbers by county or district or just overall. Is your project doing anything with those public data, or with other volunteer projects that track COVID in schools?
EO: Not at the moment. I think that we are eager to—there are a number of states that have very good dashboards, and our goal, one of the things we are working on is, how can we basically pull that in? One of the issues is that most of those dashboards just report cases, and so in order to pull them into what we’re doing, we need to go behind this and say, okay, we need to go behind and actually figure out what the initial enrollments were.
BL: Which states do you think are doing the best job so far?
EO: I mean, New York’s is pretty good. Tennessee has a pretty good dashboard. South Carolina. There’s a few.
BL: I know New York is one—I think it’s the only one that has both testing numbers and enrollment numbers. (Editor’s note: I checked; this is true.)
EO: Exactly.
BL: Last question: how do you expect the dashboard to be utilized in future research, and are you seeing any applications of it so far?
EO: No, it’s literally been, like, four days. My guess is that we will see more—we’ll see some usage by districts, as they try to think about opening, that’s the first use case. Just districts that are opening, trying to think about what’s the right thing to do. My guess is that, in the long run, maybe we’ll see some research with this. That isn’t the goal of the project, but we’ll see.
BL The focus is on helping districts compare to each other.
EO: Exactly, yeah.
Analysis
I’m excited about this dashboard. First of all, it can’t be overstated: denominators are huge. Knowing that the estimated infection rate of K-12 students in the U.S. is under one percent is so much more useful from a decision-making standpoint than the actual number of cases.
Second, the school survey model is a novel method with advantages for one specific group: the very schools included in this dataset. This dashboard is not particularly useful for me, a COVID-19 journalist, right now; its sample size is small, and the data are not currently available for download by outside users. (Oster told me that she is planning to set up a validation feature, so that she and other partners on this project can track how their data are being used.) But the school administrators who fill out the project’s biweekly surveys will be able to see COVID-19 trends for their students and staff, compared to trends at other schools across the country. They are essentially getting free consulting on their school reopening plans.
I have one major concern, however. As Oster explained in our interview, the dashboard currently includes an abundance of private and charter schools in its sample, due to partnerships with private and charter school associations.
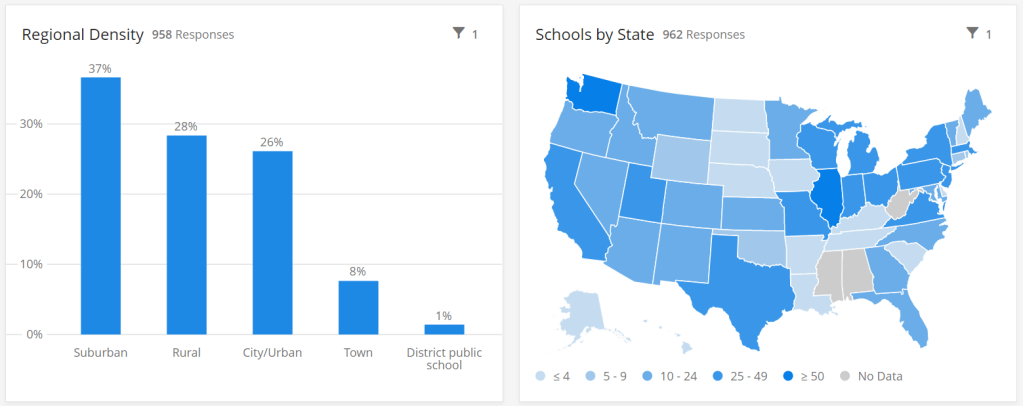
According to Education Week, public schools made up 70% of American schools in 2017-2018. In Oster’s dashboard, these schools are 67% of the sample size, while private, charter, and religious schools make up the rest of the sample. At a glance, this seems fairly representative of the country’s school demographics. However, the average public school has far more students than the average private school; without seeing the actual enrollment numbers of the schools included in this dashboard, it is difficult to determine how balanced the dashboard’s sample truly is.
In addition, the dataset’s sample so far shows a bias for suburban schools. The schools surveyed are 37% suburban, 28% rural, 26% urban, and 8% town. Suburban school districts tend to receive more funding than urban districts, and suburban districts are historically sites of school segregation. Finally, this dataset so far heavily represents private schools in Washington, with 106 schools, over 10% of the sample, coming from this state. West Virginia, Alabama, and Mississippi, all more rural states which rank in the bottom ten in U.S. News & World Report’s education rankings, are so far not represented at all.
A recent New Yorker article by Alec MacGillis draws attention to the low-income students of color who may be left behind in this era of remote learning. Students whose parents and guardians need to continue working outside the home, or otherwise do not have the resources to support kids with an array of Zoom links and homework platforms, may lose a year of education if their schools don’t reopen—and yet these students and their families are more vulnerable to COVID-19 if they do go back in person.
The schools which serve low-income minority communities are likely to need this dashboard more than any others. And yet these very schools may be left out of data collection, as their principals and superintendents may not have the bandwidth to fill out even the simplest survey. Extra effort could be needed to ensure that crucial schools are not left behind. The COVID-19 School Response Dashboard, and other future school data sources, must prioritize diversity in their data collection if they are to be truly complete.
Screenshot of Maine’s dashboard. Look at how clean this is!
Maine was actually one of my favorite state dashboards for a while. Everything is on one page. A summary section at the top makes it easy to see all the most important numbers, and then there’s a tabbed panel with mini-pages on trends and demographic data. It’s all fairly easy to navigate, and although there was a period of a few weeks where Maine’s demographic data tab never loaded for me, I never held that against the state. Maine has a clear data timestamp, and it was also one of the first states to properly separate out PCR and antibody testing numbers.
Now, however, Maine is lumping PCR and antigen tests. This means that counts of these two test are being combined in a single figure. Both PCR and antigen tests are diagnostic, but they have differing sensitivities and serve different purposes, and should be reported separately; to combine them may lead to inaccurate test positivity calculations and other issues. I expect this type of misleading reporting from, say, Florida or Rhode Island, but not from Maine. Be better, Maine!
Candid of me reading Hank Green’s new book (very good), beneath some fall foliage. It sure is great to go outside!
I like to answer questions. I’m pretty good at explaining complicated topics, and when I don’t know the answer to something, I can help someone find it. These days, that tendency manifests in everyday conversations, whether it’s with my friend from high school or a Brooklyn dad whose campsite shares a firepit with my Airbnb. I make sure the person I’m talking to knows that I’m a science journalist, and I invite them to ask me their COVID-19 questions. I do my best to be clear about where I have expertise and where I don’t, and I try to point them to sources that will fill in my gaps.
I want this newsletter to feel like one of those conversations. I started it when hospitalization data switched from the auspices of the Centers for Disease Control and Prevention (CDC) to the Department of Health and Human Services (HHS), and I realized how intensely political agendas were twisting public understanding of data in this pandemic. I wanted to answer my friends’ and family members’ questions, and I wanted to do it in a way that could also become a resource for other journalists.
This is the newsletter’s tenth week. As I took a couple of days off to unplug, it seemed a fitting time to reflect on the project’s goals and on how I’d like to move forward.
What should data reporting look like in a pandemic?
This is a question I got over the weekend. How, exactly, have the CDC and the HHS failed in their data reporting since the novel coronavirus hit America back in January?
The most important quality for a data source is transparency. Any figure will only be a one-dimensional reflection of reality; it’s impossible for figures to be fully accurate. But it is possible for sources to make public all of the decisions leading to those figures. Where did you get the data? Whom did you survey? Whom didn’t you survey? What program did you use to compile the data, to clean it, to analyze it? How did you decide which numbers to make public? What equations did you use to arrive at your averages, your trendlines, your predictions? And so on and so forth. Reliable data sources make information public, they make representatives of the analysis team available for questions, and they make announcements when a mistake has been identified.
Transparency is especially important for COVID-19 data, as infection numbers drive everything from which states’ residents are required to quarantine for two weeks when they travel, to how many ICU beds at a local hospital must be ready for patients. Journalists like me need to know what data the government is using to make decisions and where those numbers are coming from so that we can hold the government accountable; but beyond that, readers like you need to know exactly what is happening in your communities and how you can mitigate your own personal risk levels.
In my ideal data reporting scenario, representatives from the CDC or another HHS agency would be extremely public about all the COVID-19 data they’re collecting. It would publish these data in a public portal, yes, but this would be the bare minimum. This agency would publish a detailed methodology explaining how data are collected from labs, hospitals, and other clinical sites, and it would publish a detailed data dictionary written in easily accessible language.
And, most importantly, the agency would hold regular public briefings. I’m envisioning something like Governor Cuomo’s PowerPoints, but led by the actual public health experts, and with substantial time for Q&A. Agency staff should also be available to answer questions from the public and direct them to resources, such as the CDC’s pages on childcare during COVID-19 or their local registry of test sites. Finally, it should go without saying that, in my ideal scenario, every state and local government would follow the same definitions and methodology for reporting data.
Why am I doing this newsletter?
The CDC now publishes a national dataset of COVID-19 cases and deaths, and the HHS publishes a national dataset of PCR tests. Did you know about them? Have you seen any public briefings led by health experts about these data? Even as I wrote up this description, I realized how deeply our federal government has failed at even the basics of data transparency.
Research efforts and volunteer projects, such as Johns Hopkins’ COVID-19 Tracker and the COVID Tracking Project, have stepped in to fill the gap left by federal public health agencies. The COVID Tracking Project, for example, puts out daily tweets and weekly blog posts reporting on the state of COVID-19 in the U.S. I’m proud to be a small part of this vital communication effort, but I have to acknowledge that the Project does a tiny fraction of the work that an agency like the CDC would be able to mount.
Personally, I feel a responsibility to learn everything I can about COVID-19 data, and share it with an audience that can help hold me accountable to my work. So, there it is: this newsletter exists to fill a communication gap. I want to tell you what state and federal agencies are doing—or aren’t doing—to provide data on how COVID-19 is impacting Americans. And I want to help you attain some data literacy along the way. I don’t have fancy PowerPoints like Cuomo or fancy graphics like the COVID Tracking Project (though my Tableau skills are improving!). But I can ask questions, and I can answer them. I hope you’re reading this because you find that useful, and I hope this project can become more useful as it grows.
What’s next?
America is moving into what may be a long winter, with schools open and the seasonal flu incoming. (If you haven’t yet, this is your reminder: get your flu shot!) I’m in no position to hypothesize about second waves or vaccine deployment, but I do believe this pandemic will not go away any time soon.
With that in mind, I’d like to settle in this newsletter for the long haul. And I can’t do it alone. In the coming months, I want this project to become more reader-focused. Here are a couple of ideas I have about how to make that happen; please reach out if you have others!
Reader-driven topics: Thus far, the subjects of this newsletter have been driven by whatever I am excited and/or angry about in a given week. I would like to broaden this to also include news items, data sources, and other topics that come from you.
Answering your questions: Is there a COVID-19 metric that you’ve seen in news articles, but aren’t sure you understand? Is there a data collection process that you’d like to know more about? Is there a seemingly-simple thing about the virus that you’ve been afraid to ask anywhere else? Send me your COVID-19 questions, data or otherwise, and I will do my best to answer.
Collecting data sources: In the first nine weeks of this project, I’ve featured a lot of data sources, and the number will only grow as I continue. It might be helpful if I put all those sources together into one public spreadsheet to make a master resource, huh? (I am a little embarrassed that I didn’t think of this one sooner.) I’ll work on this spreadsheet, and share it with you all next week.
Events?? One of my goals with this project is data literacy, and I’d like to make that work a little more hands-on. I’m thinking about potential online workshops and collaborations with other organizations. I’m also looking into potential funding options for such events; there will hopefully be more news to come on this front in the coming weeks.